
Bayesovské vzorce ano. Vzorec celkové pravděpodobnosti a Bayesovy vzorce
kdo je Bayes? a co to má společného s managementem? - může následovat zcela férová otázka. Prozatím mě berte za slovo: je to velmi důležité!... a zajímavé (alespoň pro mě).
Jaké je paradigma, ve kterém funguje většina manažerů: Pokud něco pozoruji, jaké z toho mohu vyvodit závěry? Co učí Bayes: co tam skutečně musí být, abych to mohl pozorovat? Přesně tak se vyvíjejí všechny vědy a o tom píše (cituji zpaměti): člověk, který nemá v hlavě teorii, pod vlivem různých událostí (pozorování) uhýbá od jedné myšlenky k druhé. Ne nadarmo se říká: není nic praktičtějšího než dobrá teorie.
Příklad z praxe. Můj podřízený udělá chybu a můj kolega (vedoucí jiného oddělení) říká, že by bylo potřeba na nedbalého zaměstnance uplatnit manažerský vliv (jinými slovy potrestat/nadávat). A vím, že tento zaměstnanec provede 4–5 tisíc operací stejného typu měsíčně a během této doby neudělá více než 10 chyb. Cítíte rozdíl v paradigmatu? Kolegyně na pozorování reaguje a já mám apriorně známo, že zaměstnanec dělá určitý počet chyb, takže další tuto znalost neovlivnila... Nyní, pokud se na konci měsíce ukáže, že jsou, třeba 15 takových chyb!.. To už bude důvod ke studiu důvodů nedodržování norem.
Jste přesvědčeni o důležitosti bayesovského přístupu? Zaujalo? Doufám, že ano. A teď ta moucha. Bohužel, Bayesovské myšlenky jsou jen zřídka uvedeny hned. Upřímně řečeno jsem měl smůlu, protože jsem se s těmito myšlenkami seznámil prostřednictvím populární literatury, po přečtení, po které zůstalo mnoho otázek. Když jsem plánoval napsat poznámku, shromáždil jsem vše, co jsem si předtím dělal poznámky na Bayes, a také jsem studoval, co bylo napsáno na internetu. Předkládám vaší pozornosti svůj nejlepší odhad na toto téma. Úvod do Bayesovské pravděpodobnosti.
Odvození Bayesovy věty
Uvažujme následující experiment: zavoláme libovolné číslo ležící na segmentu a zaznamenáme, kdy je toto číslo například mezi 0,1 a 0,4 (obr. 1a). Pravděpodobnost této události se rovná poměru délky segmentu k celkové délce segmentu za předpokladu, že výskyt čísel na segmentu stejně pravděpodobné. Matematicky se to dá napsat p(0,1 <= x <= 0,4) = 0,3, или кратко r(X) = 0,3, kde r- pravděpodobnost, X– náhodná veličina v rozsahu , X– náhodná veličina v rozsahu . To znamená, že pravděpodobnost zasažení segmentu je 30 %.

Rýže. 1. Grafická interpretace pravděpodobností
Nyní uvažujme čtverec x (obr. 1b). Řekněme, že musíme pojmenovat dvojice čísel ( x, y), z nichž každá je větší než nula a menší než jedna. Pravděpodobnost, že x(první číslo) bude v rámci segmentu (modrá oblast 1), rovná se poměru plochy modré plochy k ploše celého čtverce, tedy (0,4 – 0,1) * (1 – 0 ) / (1 * 1) = 0, 3, tedy stejných 30 %. Pravděpodobnost, že y umístěný uvnitř segmentu (zelená plocha 2) se rovná poměru plochy zelené plochy k ploše celého náměstí p(0,5 <= y <= 0,7) = 0,2, или кратко r(Y) = 0,2.
Co se zároveň můžete naučit o hodnotách? x A y. Jaká je například pravděpodobnost, že ve stejnou dobu x A y jsou v odpovídajících daných segmentech? Chcete-li to provést, musíte vypočítat poměr plochy oblasti 3 (průsečík zeleného a modrého pruhu) k ploše celého čtverce: p(X, Y) = (0,4 – 0,1) * (0,7 – 0,5) / (1 * 1) = 0,06.
Nyní řekněme, že chceme vědět, jaká je to pravděpodobnost y je v intervalu if x je již v dosahu . To znamená, že ve skutečnosti máme filtr a když voláme páry ( x, y), pak ty dvojice, které nesplňují podmínku pro nalezení, ihned vyřadíme x v daném intervalu a pak z vyfiltrovaných dvojic počítáme ty, pro které y splňuje naši podmínku a považuje pravděpodobnost za poměr počtu párů, pro které y leží ve výše uvedeném segmentu k celkovému počtu filtrovaných párů (tj x leží v segmentu). Tuto pravděpodobnost můžeme zapsat jako p(Y|X na X zasáhnout dostřel." Je zřejmé, že tato pravděpodobnost se rovná poměru plochy plochy 3 k ploše modré plochy 1. Plocha plochy 3 je (0,4 – 0,1) * (0,7 – 0,5) = 0,06 a plocha modré plochy 1 ( 0,4 – 0,1) * (1 – 0) = 0,3, pak je jejich poměr 0,06 / 0,3 = 0,2. Jinými slovy pravděpodobnost nalezení y na segmentu za předpokladu, že x patří do segmentu p(Y|X) = 0,2.
V předchozím odstavci jsme vlastně formulovali identitu: p(Y|X) = p(X, Y) / p( X). Zní: „pravděpodobnost zasažení na v rozsahu , za předpokladu, že X zásah do rozsahu, který se rovná poměru pravděpodobnosti současného zásahu X do rozsahu a na na dostřel, na pravděpodobnost zásahu X do rozsahu."
Analogicky zvažte pravděpodobnost p(X|Y). Voláme páry ( x, y) a filtrovat ty, pro které y leží mezi 0,5 a 0,7, pak pravděpodobnost, že x je v intervalu za předpokladu, že y patří do segmentu se rovná poměru plochy regionu 3 k ploše zelené oblasti 2: p(X|Y) = p(X, Y) / p(Y).
Všimněte si, že pravděpodobnosti p(X, Y) A p(Y, X) jsou stejné a obě se rovnají poměru plochy zóny 3 k ploše celého čtverce, ale pravděpodobnosti p(Y|X) A p(X|Y) nejsou si rovni; zatímco pravděpodobnost p(Y|X) se rovná poměru plochy regionu 3 k regionu 1 a p(X|Y) – region 3 až region 2. Všimněte si také, že p(X, Y) se často označuje jako p(X&Y).
Zavedli jsme tedy dvě definice: p(Y|X) = p(X, Y) / p( X) A p(X|Y) = p(X, Y) / p(Y)
Přepišme tyto rovnosti do tvaru: p(X, Y) = p(Y|X) * p( X) A p(X, Y) = p(X|Y) * p(Y)
Protože jsou levé strany stejné, pravé strany jsou stejné: p(Y|X) * p( X) = p(X|Y) * p(Y)
Nebo můžeme poslední rovnost přepsat jako:

To je Bayesova věta!
Opravdu takové jednoduché (téměř tautologické) transformace dávají vzniknout skvělé větě!? Nespěchejte se závěry. Pojďme si znovu promluvit o tom, co jsme dostali. Byla zde určitá počáteční (a priori) pravděpodobnost r(X), tedy náhodná veličina X rovnoměrně rozložené na segmentu spadá do rozsahu X. Došlo k události Y, v důsledku čehož jsme obdrželi zadní pravděpodobnost stejné náhodné veličiny X: r(X|Y), a tato pravděpodobnost se liší od r(X) koeficientem. Událost Y nazývané důkazy, víceméně potvrzující nebo vyvracející X. Tento koeficient se někdy nazývá důkazní síla. Čím silnější je důkaz, tím více skutečnost pozorování Y mění předchozí pravděpodobnost, tím více se zadní pravděpodobnost liší od předchozí. Pokud jsou důkazy slabé, je zadní pravděpodobnost téměř stejná jako předchozí.
Bayesův vzorec pro diskrétní náhodné veličiny
V předchozí části jsme odvodili Bayesův vzorec pro spojité náhodné veličiny x a y definované na intervalu. Uvažujme příklad s diskrétními náhodnými proměnnými, z nichž každá nabývá dvou možných hodnot. Při běžných lékařských prohlídkách bylo zjištěno, že ve věku čtyřiceti let trpí rakovinou prsu 1 % žen. 80 % žen s rakovinou má pozitivní výsledky mamografie. 9,6 % zdravých žen má také pozitivní výsledky mamografie. Při vyšetření měla žena v této věkové skupině pozitivní výsledek mamografie. Jaká je pravděpodobnost, že skutečně má rakovinu prsu?
Linka uvažování/výpočtů je následující. Z 1 % pacientů s rakovinou poskytne mamografie 80 % pozitivních výsledků = 1 % * 80 % = 0,8 %. Z 99 % zdravých žen poskytne mamografie 9,6 % pozitivních výsledků = 99 % * 9,6 % = 9,504 %. Celkem 10,304 % (9,504 % + 0,8 %) s pozitivními výsledky mamografie, pouze 0,8 % je nemocných a zbývajících 9,504 % je zdravých. Pravděpodobnost, že žena s pozitivním mamografem má rakovinu, je tedy 0,8 % / 10,304 % = 7,764 %. Mysleli jste 80% nebo tak?
V našem příkladu má Bayesův vzorec následující podobu:
Promluvme si ještě jednou o „fyzickém“ významu tohoto vzorce. X– náhodná veličina (diagnóza), nabývající hodnot: X 1- nemocný a X 2- zdravý; Y– náhodná veličina (výsledek měření – mamografie), nabývající hodnot: Y 1- pozitivní výsledek a Y2– negativní výsledek; p(X 1)– pravděpodobnost onemocnění před mamografií (a priori pravděpodobnost) rovna 1 %; p(Y 1 |X 1 ) – pravděpodobnost pozitivního výsledku, pokud je pacient nemocný (podmíněná pravděpodobnost, protože musí být specifikována v podmínkách úlohy), rovná 80 %; p(Y 1 |X 2 ) – pravděpodobnost pozitivního výsledku, pokud je pacient zdravý (také podmíněná pravděpodobnost) je 9,6 %; p(X 2)– pravděpodobnost, že je pacientka před mamografií zdravá (a priori pravděpodobnost) je 99 %; p(X1|Y 1 ) – pravděpodobnost, že je pacientka nemocná při pozitivním výsledku mamografie (zadní pravděpodobnost).
Je vidět, že zadní pravděpodobnost (to, co hledáme) je úměrná předchozí pravděpodobnosti (počáteční) s poněkud složitějším koeficientem  . Dovolte mi znovu zdůraznit. Podle mého názoru je to základní aspekt bayesovského přístupu. Měření ( Y) přidal určité množství informací k tomu, co bylo původně k dispozici (a priori), což objasnilo naše znalosti o objektu.
. Dovolte mi znovu zdůraznit. Podle mého názoru je to základní aspekt bayesovského přístupu. Měření ( Y) přidal určité množství informací k tomu, co bylo původně k dispozici (a priori), což objasnilo naše znalosti o objektu.
Příklady
Chcete-li konsolidovat materiál, který jste probrali, zkuste vyřešit několik problémů.
Příklad 1 Jsou tam 3 urny; v první jsou 3 bílé koule a 1 černá; ve druhém - 2 bílé koule a 3 černé; ve třetí jsou 3 bílé koule. Někdo se náhodně přiblíží k jedné z uren a vyjme z ní 1 míček. Tato koule se ukázala jako bílá. Najděte zadní pravděpodobnost, že míček je vytažen z 1., 2., 3. urny.
Řešení. Máme tři hypotézy: H 1 = (je vybrána první urna), H 2 = (je vybrána druhá urna), H 3 = (je vybrána třetí urna). Protože je urna vybrána náhodně, apriorní pravděpodobnosti hypotéz jsou stejné: P(H 1) = P(H 2) = P(H 3) = 1/3.
V důsledku experimentu se objevila událost A = (z vybrané urny byla vytažena bílá koule). Podmíněné pravděpodobnosti události A za hypotézy H 1, H 2, H 3: P(A|H 1) = 3/4, P(A|H 2) = 2/5, P(A|H 3) = 1. Například první rovnost zní takto: „pravděpodobnost vytažení bílé koule, pokud je vybrána první urna, je 3/4 (protože v první urně jsou 4 koule a 3 z nich jsou bílé).“
Pomocí Bayesova vzorce najdeme zadní pravděpodobnosti hypotéz:

Ve světle informací o výskytu události A se tedy změnily pravděpodobnosti hypotéz: hypotéza H 3 se stala nejpravděpodobnější, hypotéza H 2 se stala nejméně pravděpodobnou.
Příklad 2 Dva střelci nezávisle střílejí na stejný cíl, každý vystřelí jednu ránu. Pravděpodobnost zasažení cíle pro prvního střelce je 0,8, pro druhého - 0,4. Po střelbě byla objevena jedna díra v terči. Najděte pravděpodobnost, že tato jamka patří prvnímu střelci (Výsledek (obě jamky se shodují) je zahozen jako zanedbatelně nepravděpodobný).
Řešení. Před experimentem jsou možné následující hypotézy: H 1 = (nezasáhne první ani druhý šíp), H 2 = (zasáhnou oba šípy), H 3 - (první střelec zasáhne, druhý nezasáhne). ), H 4 = (první střelec nezasáhne a druhý zasáhne). Předchozí pravděpodobnosti hypotéz:
P(Hi) = 0,2 x 0,6 = 0,12; P(H2) = 0,8 x 0,4 = 0,32; P (H3) = 0,8 * 0,6 = 0,48; P(H4) = 0,2 x 0,4 = 0,08.
Podmíněné pravděpodobnosti pozorovaného jevu A = (v cíli je jedna díra) se za těchto hypotéz rovnají: P(A|H 1) = P(A|H 2) = 0; P(A|H3) = P(A|H4) = 1
Po experimentu se hypotézy H 1 a H 2 stanou nemožnými a zadní pravděpodobnosti hypotéz H 3 a H 4 podle Bayesova vzorce budou:

Bayes proti spamu
Bayesův vzorec našel široké uplatnění při vývoji spamových filtrů. Řekněme, že chcete trénovat počítač, aby určil, které e-maily jsou spam. Budeme vycházet ze slovníku a frází pomocí bayesovských odhadů. Vytvořme nejprve prostor pro hypotézy. Mějme dvě hypotézy týkající se jakéhokoli dopisu: H A je spam, H B není spam, ale normální, nezbytný dopis.
Nejprve si „natrénujme“ náš budoucí antispamový systém. Vezmeme všechna písmena, která máme, a rozdělíme je na dvě „hromady“ po 10 písmenech. Do jednoho dáme spamové emaily a nazveme ho halda H A, do druhého dáme potřebnou korespondenci a nazveme ho halda H B. Nyní se podívejme: jaká slova a fráze se nacházejí ve spamu a nezbytných dopisech a s jakou frekvencí? Tato slova a fráze nazveme důkazy a označíme je E 1 , E 2 ... Ukazuje se, že běžně používaná slova (například slova „jako“, „vaše“) v hromadách H A a H B se vyskytují přibližně s stejnou frekvenci. Přítomnost těchto slov v dopise nám tedy neříká nic o tom, ke které hromádce je přiřadit (slabé důkazy). Přiřaďme těmto slovům neutrální skóre pravděpodobnosti „spamu“, řekněme 0,5.
Nechte frázi „mluvená angličtina“ se objevit pouze v 10 písmenech a častěji ve spamových dopisech (například v 7 spamových dopisech ze všech 10) než v nezbytných (ve 3 z 10). Dejte této frázi vyšší hodnocení pro spam: 7/10 a nižší hodnocení pro normální e-maily: 3/10. Naopak se ukázalo, že slovo „buddy“ se častěji objevovalo normálními písmeny (6 z 10). A pak jsme dostali krátký dopis: „Můj příteli! Jak se mluví anglicky?". Zkusme zhodnotit jeho „spamovost“. Uvedeme obecné odhady P(H A), P(H B) náležející písmenu ke každé hromadě pomocí poněkud zjednodušeného Bayesova vzorce a našich přibližných odhadů:
P(HA) = A/(A+B), Kde A = p a1 *p a2 *…*p an , B = p b1 *p b2 *…*p b n = (1 – p a1)*(1 – p a2)*… *(1 – p an).
Tabulka 1. Zjednodušený (a neúplný) Bayesův odhad psaní.

Náš hypotetický dopis tedy získal skóre pravděpodobnosti příslušnosti s důrazem na „spam“. Můžeme se rozhodnout hodit dopis na jednu z hromádek? Pojďme nastavit prahy rozhodování:
- Budeme předpokládat, že písmeno patří do hromady H i, pokud P(H i) ≥ T.
- Písmeno nepatří do haldy, pokud P(H i) ≤ L.
- Jestliže L ≤ P(H i) ≤ T, pak nelze učinit žádné rozhodnutí.
Můžete vzít T = 0,95 a L = 0,05. Od pro dotyčné písmeno a 0,05< P(H A) < 0,95, и 0,05 < P(H В) < 0,95, то мы не сможем принять решение, куда отнести данное письмо: к спаму (H A) или к нужным письмам (H B). Можно ли улучшить оценку, используя больше информации?
Ano. Spočítejme skóre pro každý důkaz jiným způsobem, jak to ve skutečnosti navrhl Bayes. Nechat:
F a je celkový počet nevyžádaných e-mailů;
F ai je počet písmen s certifikátem i v hromadě spamu;
Fb je celkový počet potřebných písmen;
F bi je počet písmen s certifikátem i ve hromadě potřebných (relevantních) písmen.
Potom: p ai = F ai /Fa, pbi = Fbi /Fb. P(H A) = A/(A+B), P(H B) = B/(A+B), Kde A = p a1 *p a2 *…*p an , B = p b1 *p b2 *…*p b n
Vezměte prosím na vědomí, že hodnocení důkazních slov p ai a p bi se stalo objektivním a lze je vypočítat bez lidského zásahu.
Tabulka 2. Přesnější (ale neúplný) Bayesův odhad založený na dostupných funkcích z dopisu

Dostali jsme velmi jednoznačný výsledek - s velkou výhodou lze písmeno klasifikovat jako požadované písmeno, protože P(H B) = 0,997 > T = 0,95. Proč se výsledek změnil? Protože jsme použili více informací - vzali jsme v úvahu počet písmen v každé z hromádek a mimochodem mnohem správněji určili odhady p ai a p bi. Určili jsme je stejným způsobem jako sám Bayes, a to výpočtem podmíněných pravděpodobností. Jinými slovy, p a3 je pravděpodobnost výskytu slova „kamarád“ v dopise za předpokladu, že toto písmeno již patří do haldy nevyžádané pošty H A . Výsledek na sebe nenechal dlouho čekat – zdá se, že se můžeme rozhodnout s větší jistotou.
Bayes proti korporátním podvodům
Zajímavou aplikaci Bayesovského přístupu popsal MAGNUS8.
Můj aktuální projekt (IS pro odhalování podvodů ve výrobním podniku) využívá Bayesův vzorec ke stanovení pravděpodobnosti podvodu (podvodu) za přítomnosti/nepřítomnosti několika skutečností, které nepřímo svědčí ve prospěch hypotézy o možnosti spáchání podvodu. Algoritmus se samoučí (se zpětnou vazbou), tzn. přepočítává své koeficienty (podmíněné pravděpodobnosti) při skutečném potvrzení či nepotvrzení podvodu při kontrole ze strany ekonomické bezpečnostní služby.
Pravděpodobně stojí za to říci, že takové metody při navrhování algoritmů vyžadují poměrně vysokou matematickou kulturu vývojáře, protože sebemenší chyba při odvozování a/nebo implementaci výpočetních vzorců anuluje a zdiskredituje celou metodu. Pravděpodobnostní metody jsou k tomu obzvláště náchylné, protože lidské myšlení není uzpůsobeno pro práci s pravděpodobnostními kategoriemi, a proto neexistuje žádná „viditelnost“ a pochopení „fyzického významu“ středních a konečných pravděpodobnostních parametrů. Toto chápání existuje pouze pro základní pojmy teorie pravděpodobnosti a pak stačí velmi pečlivě kombinovat a odvozovat složité věci podle zákonů teorie pravděpodobnosti – u složených objektů už zdravý rozum nepomůže. S tím jsou spojeny zejména docela vážné metodologické bitvy odehrávající se na stránkách moderních knih o filozofii pravděpodobnosti a také velké množství sofismů, paradoxů a kuriózních hádanek na toto téma.
Další nuance, které jsem musel čelit, je, že bohužel téměř vše, co je na toto téma více či méně UŽITEČNÉ V PRAXI, je napsáno v angličtině. V ruskojazyčných zdrojích je převážně jen známá teorie s demonstračními příklady jen pro ty nejprimitivnější případy.
S poslední poznámkou naprosto souhlasím. Například Google, když se snažil najít něco jako „kniha Bayesian Probability“, nevytvořil nic srozumitelného. Pravda, hlásil, že kniha s bayesovskými statistikami byla v Číně zakázána. (Profesor statistiky Andrew Gelman informoval na blogu Kolumbijské univerzity, že jeho kniha Analýza dat s regresí a víceúrovňovými/hierarchickými modely byla v Číně zakázána. Vydavatel tam uvedl, že „kniha nebyla schválena úřady kvůli různým politicky citlivým materiál v textu.") Zajímalo by mě, zda podobný důvod vedl k nedostatku knih o bayesovské pravděpodobnosti v Rusku?
Konzervatismus ve zpracování lidských informací
Pravděpodobnosti určují míru nejistoty. Pravděpodobnost, jak podle Bayese, tak podle naší intuice, je prostě číslo mezi nulou a číslem, které představuje míru, do jaké poněkud idealizovaný člověk věří, že tvrzení je pravdivé. Důvod, proč je člověk poněkud idealizován, je ten, že součet jeho pravděpodobností pro dvě vzájemně se vylučující události se musí rovnat pravděpodobnosti, že nastane kterákoli událost. Vlastnost aditivity má takové důsledky, že se se všemi může setkat jen málo skutečných lidí.
Bayesův teorém je triviálním důsledkem vlastnosti aditivity, nezpochybnitelný a dohodnutý všemi pravděpodobnostmi, bayesovskými i jinými. Jedním ze způsobů, jak to napsat, je následující. Jestliže P(HA |D) je následná pravděpodobnost, že hypotéza A byla po pozorování dané hodnoty D, P(HA) je její předchozí pravděpodobnost před pozorováním dané hodnoty D, P(D|HA ) je pravděpodobnost, že a daná hodnota D bude pozorována, pokud H A platí a P(D) je nepodmíněná pravděpodobnost dané hodnoty D, pak
(1) P(HA |D) = P(D|HA) * P(HA) / P(D)
P(D) je nejlépe chápat jako normalizační konstantu, která způsobuje, že se zadní pravděpodobnosti sčítají do jednoty přes vyčerpávající soubor vzájemně se vylučujících hypotéz, které jsou zvažovány. Pokud je potřeba to vypočítat, mohlo by to být takto:
Ale častěji je P(D) spíše eliminováno než vypočteno. Pohodlný způsob, jak to eliminovat, je transformovat Bayesovu větu do formy poměru pravděpodobnost-odds.
Zvažte další hypotézu, H B , která se vzájemně vylučuje s H A , a změňte svůj názor na to na základě stejné dané veličiny, která změnila váš názor na H A
(2) P(H B | D) = P(D|H B) * P(H B) / P(D)
Nyní vydělme rovnici 1 rovnicí 2; výsledek bude takový:

kde Ω 1 jsou pozdější šance ve prospěch H A až H B , Ω 0 jsou předchozí šance a L je množství známé statistikům jako poměr pravděpodobnosti. Rovnice 3 je stejnou relevantní verzí Bayesovy věty jako rovnice 1 a je často výrazně užitečnější zejména pro experimenty zahrnující hypotézy. Bayesians tvrdí, že Bayesův teorém je formálně optimálním pravidlem, jak revidovat názory ve světle nových důkazů.
Zajímá nás srovnání ideálního chování definovaného Bayesovým teorémem se skutečným chováním lidí. Abyste měli představu, co to znamená, zkusme experiment s vámi jako testovacím subjektem. Tato taška obsahuje 1000 pokerových žetonů. Mám dva takové sáčky, jeden obsahuje 700 červených a 300 modrých žetonů a druhý obsahuje 300 červených a 700 modrých. Hodil jsem si minci, abych se rozhodl, kterou použít. Pokud jsou tedy naše názory stejné, vaše současná pravděpodobnost, že získáte sáček obsahující více červených žetonů, je 0,5. Nyní vytvoříte náhodný vzorek s návratem po každém čipu. Ve 12 žetonech získáte 8 červených a 4 modré. Nyní, na základě všeho, co víte, jaká je pravděpodobnost, že přistane taška s nejvíce červenými? Je jasné, že je vyšší než 0,5. Prosím, nepokračujte ve čtení, dokud nezaznamenáte své skóre.
Pokud jste jako typický účastník testu, vaše skóre kleslo v rozmezí 0,7 až 0,8. Pokud bychom však provedli odpovídající výpočet, odpověď by byla 0,97. Je skutečně velmi vzácné, aby člověk, u kterého se předtím neprokázal vliv konzervatismu, dospěl k tak vysokému odhadu, i když znal Bayesovu větu.
Pokud je podíl červených žetonů v sáčku r, pak pravděpodobnost přijetí rčervené žetony a ( n –r) modrá dovnitř n vzorky s návratem - p r (1–p)n–r. Takže v typickém experimentu se sáčkem a pokerovými žetony, pokud NA znamená, že podíl červených žetonů je p A A NB– znamená, že podíl je rB, pak poměr pravděpodobnosti:

Při aplikaci Bayesova vzorce je třeba vzít v úvahu pouze pravděpodobnost skutečného pozorování a ne pravděpodobnosti jiných pozorování, která mohl provést, ale neudělal. Tento princip má široké důsledky pro všechny statistické a nestatistické aplikace Bayesova teorému; je to nejdůležitější technický nástroj pro Bayesovské uvažování.
Bayesovská revoluce
Vaši přátelé a kolegové mluví o něčem, co se nazývá "Bayesův teorém" nebo "Bayesovo pravidlo" nebo něco, čemu se říká Bayesovské uvažování. Opravdu je to zajímá, takže jdete online a najdete stránku o Bayesově teorému a... Je to rovnice. A je to... Proč matematický koncept vyvolává takové nadšení v myslích? Jaký druh „Bayesovské revoluce“ se děje mezi vědci a tvrdí se, že i samotný experimentální přístup lze označit za její zvláštní případ? Jaké je tajemství, které Bayesané znají? Jaké světlo vidí?
Bayesovská revoluce ve vědě nenastala, protože stále více kognitivních vědců si najednou začalo všímat, že mentální jevy mají bayesovskou strukturu; ne proto, že by vědci ve všech oblastech začali používat Bayesovu metodu; ale protože věda sama je zvláštním případem Bayesovy věty; experimentální důkaz je Bayesovský důkaz. Bayesovští revolucionáři tvrdí, že když provedete experiment a získáte důkazy, které „potvrzují“ nebo „vyvracejí“ vaši teorii, dojde k potvrzení nebo vyvrácení podle Bayesovských pravidel. Například musíte vzít v úvahu nejen to, že vaše teorie může vysvětlit jev, ale také to, že existují další možná vysvětlení, která mohou tento jev také předpovídat.
Dříve byla nejoblíbenější filozofií vědy stará filozofie, kterou vytlačila Bayesovská revoluce. Myšlenka Karla Poppera, že teorie mohou být zcela zfalšovány, ale nikdy plně ověřeny, je dalším zvláštním případem Bayesovských pravidel; pokud p(X|A) ≈ 1 – pokud teorie dělá správné předpovědi, pak pozorování ~X falzifikuje A velmi silně. Na druhou stranu, pokud p(X|A) ≈ 1 a pozorujeme X, toto silně nepotvrzuje teorie; možná je možná nějaká jiná podmínka B, taková, že p(X|B) ≈ 1, a za které pozorování X nesvědčí ve prospěch A, ale svědčí ve prospěch B. Aby pozorování X definitivně potvrdilo A, měli bychom nevědět, že to p(X|A) ≈ 1 a že p(X|~A) ≈ 0, což nemůžeme vědět, protože nemůžeme zvážit všechna možná alternativní vysvětlení. Když například Einsteinova teorie obecné relativity překonala Newtonovu dobře podporovanou teorii gravitace, učinila všechny předpovědi Newtonovy teorie zvláštním případem předpovědí Einsteinových.
Podobně lze Popperovo tvrzení, že myšlenka musí být falzifikovatelná, interpretovat jako projev Bayesova pravidla zachování pravděpodobnosti; jestliže výsledek X je pozitivní důkaz pro teorii, pak výsledek ~X musí vyvrátit teorii do jisté míry. Pokud se pokusíte interpretovat X i ~X jako „potvrzující“ teorii, Bayesovská pravidla říkají, že je to nemožné! Chcete-li zvýšit pravděpodobnost teorie, musíte ji podrobit testům, které mohou potenciálně snížit její pravděpodobnost; Není to jen pravidlo pro identifikaci šarlatánů ve vědě, ale důsledek Bayesovské věty pravděpodobnosti. Na druhou stranu Popperova myšlenka, že je potřeba pouze falšování a není potřeba žádné potvrzení, je nesprávná. Bayesův teorém ukazuje, že falsifikace je ve srovnání s potvrzením velmi silným důkazem, ale falsifikace má stále pravděpodobnostní povahu; neřídí se zásadně odlišnými pravidly a neliší se tímto způsobem od potvrzení, jak tvrdí Popper.
Zjišťujeme tedy, že mnoho jevů v kognitivních vědách, plus statistické metody používané vědci, plus samotná vědecká metoda, to vše jsou speciální případy Bayesova teorému. Toto je Bayesovská revoluce.
Vítejte v Bayesian Conspiracy!
Literatura o Bayesovské pravděpodobnosti
2. Mnoho různých Bayesových aplikací popisuje laureát Nobelovy ceny za ekonomii Kahneman (a jeho soudruzi) v nádherné knize. Jen ve svém krátkém shrnutí této velmi rozsáhlé knihy jsem napočítal 27 zmínek o jménu presbyteriánského kazatele. Minimální vzorce. (.. moc se mi to líbilo. Pravda, je to trochu složité, je tam hodně matematiky (a kde bychom bez ní byli), ale jednotlivé kapitoly (např. kapitola 4. Informace) jsou vyloženě k tématu. Doporučuji všem I když je pro vás matematika obtížná, přečtěte si každý druhý řádek, vynechejte matematiku a lovte užitečná zrna...
14. (dodatek ze dne 15.1.2017), kapitola z knihy Tonyho Crillyho. 50 nápadů, o kterých byste měli vědět. Matematika.
Nositel Nobelovy ceny za fyziku Richard Feynman, když mluvil o jednom filozofovi s obzvláště velkou sebedůležitostí, jednou řekl: „To, co mě dráždí, není filozofie jako věda, ale pompéznost, která se kolem ní vytváří. Kdyby se tak filozofové mohli smát sami sobě! Kdyby tak mohli říct: „Říkám, že je to takhle, ale von Leipzig si myslel, že je to jinak, a také o tom něco ví. Kdyby si jen nezapomněli ujasnit, že je to jen jejich .
Bayesův vzorec:Pravděpodobnosti P(H i) hypotéz H i se nazývají apriorní pravděpodobnosti - pravděpodobnosti před prováděním experimentů.
Pravděpodobnosti P(A/H i) se nazývají posteriorní pravděpodobnosti - pravděpodobnosti hypotéz H i, upřesněné na základě zkušenosti.
Příklad č. 1. Zařízení lze sestavit z kvalitních dílů i z dílů běžné kvality. Asi 40 % zařízení je sestaveno z vysoce kvalitních dílů. Pokud je zařízení sestaveno z kvalitních dílů, je jeho spolehlivost (pravděpodobnost bezporuchového provozu) v čase t 0,95; pokud je vyroben z dílů běžné kvality, je jeho spolehlivost 0,7. Zařízení bylo testováno na čas t a fungovalo bezchybně. Najděte pravděpodobnost, že je vyroben z vysoce kvalitních dílů.
Řešení. Jsou možné dvě hypotézy: H 1 - zařízení je sestaveno z vysoce kvalitních dílů; H 2 - zařízení je sestaveno z dílů běžné kvality. Pravděpodobnosti těchto hypotéz před experimentem: P(H 1) = 0,4, P(H 2) = 0,6. V důsledku experimentu byla pozorována událost A - zařízení pracovalo po dobu t bezchybně. Podmíněné pravděpodobnosti této události za hypotézy H 1 a H 2 jsou stejné: P(A|H 1) = 0,95; P(A|H2) = 0,7. Pomocí vzorce (12) zjistíme pravděpodobnost hypotézy H 1 po experimentu:
![]()
Příklad č. 2. Dva střelci střílejí na stejný cíl nezávisle na sobě, každý vystřelí jednu ránu. Pravděpodobnost zasažení terče u prvního střelce je 0,8, u druhého 0,4. Po střelbě byla objevena jedna díra v terči. Za předpokladu, že dva střelci nemohou zasáhnout stejný bod, zjistěte pravděpodobnost, že první střelec zasáhne cíl.
Řešení. Nechť událost A - po střelbě je detekována jedna díra v terči. Před začátkem natáčení jsou možné hypotézy:
H 1 - nezasáhne první ani druhý střelec, pravděpodobnost této hypotézy: P(H 1) = 0,2 · 0,6 = 0,12.
H 2 - zasáhnou oba střelci, P(H 2) = 0,8 · 0,4 = 0,32.
H 3 - první střelec zasáhne, ale druhý nezasáhne, P(H 3) = 0,8 · 0,6 = 0,48.
H 4 - první střelec nezasáhne, ale zasáhne druhý, P (H 4) = 0,2 · 0,4 = 0,08.
Podmíněné pravděpodobnosti události A podle těchto hypotéz jsou stejné:
Po experimentu se hypotézy H 1 a H 2 stanou nemožnými a pravděpodobnosti hypotéz H 3 a H 4
bude se rovnat:
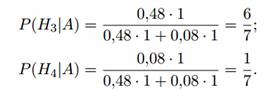
Je tedy velmi pravděpodobné, že cíl zasáhl první střelec.
Příklad č. 3. V montážní dílně je k zařízení připojen elektromotor. Elektromotory dodávají tři výrobci. Sklad obsahuje elektromotory ze jmenovaných továren v množství 19,6 respektive 11 kusů, které mohou fungovat bez poruchy až do konce záruční doby, respektive s pravděpodobnostmi 0,85, 0,76 a 0,71. Pracovník náhodně sebere jeden motor a namontuje jej na zařízení. Najděte pravděpodobnost, že elektromotor nainstalovaný a bezporuchový provoz až do konce záruční doby byl dodán prvním, druhým nebo třetím výrobcem.
Řešení. První zkouškou je výběr elektromotoru, druhým chod elektromotoru v záruční době. Zvažte následující události:
A - elektromotor pracuje bez poruchy až do konce záruční doby;
H 1 - montér odebere motor z výroby prvního závodu;
H 2 - montér odebere motor z výroby druhého závodu;
H 3 - montér odebere motor z výroby třetího závodu.
Pravděpodobnost události A se vypočítá pomocí vzorce celkové pravděpodobnosti:
Podmíněné pravděpodobnosti jsou uvedeny v prohlášení o problému:
Pojďme najít pravděpodobnosti
Pomocí Bayesových vzorců (12) vypočítáme podmíněné pravděpodobnosti hypotéz H i:

Příklad č. 4. Pravděpodobnosti, že během provozu systému, který se skládá ze tří prvků, selžou prvky očíslované 1, 2 a 3, jsou v poměru 3 : 2 : 5. Pravděpodobnost detekce poruch těchto prvků je rovna 0,95; 0,9 a 0,6.
b) Za podmínek této úlohy byla zjištěna porucha během provozu systému. Který prvek s největší pravděpodobností selhal?
Řešení.
Nechť A je událost selhání. Zaveďme soustavu hypotéz H1 - porucha prvního prvku, H2 - porucha druhého prvku, H3 - porucha třetího prvku.
Najdeme pravděpodobnosti hypotéz:
P(Hl) = 3/(3+2+5) = 0,3
P(H2) = 2/(3+2+5) = 0,2
P(H3) = 5/(3+2+5) = 0,5
Podle podmínek problému se podmíněné pravděpodobnosti události A rovnají:
P(A|H1) = 0,95, P(A|H2) = 0,9, P(A|H3) = 0,6
a) Najděte pravděpodobnost detekce poruchy v systému.
P(A) = P(H1)*P(A|H1) + P(H2)*P(A|H2) + P(H3)*P(A|H3) = 0,3*0,95 + 0,2*0,9 + 0,5 *0,6 = 0,765
b) Za podmínek této úlohy byla zjištěna porucha během provozu systému. Který prvek s největší pravděpodobností selhal?
P1 = P(H1)*P(A|H1)/ P(A) = 0,3*0,95 / 0,765 = 0,373
P2 = P(H2)*P(A|H2)/ P(A) = 0,2*0,9 / 0,765 = 0,235
P3 = P(H3)*P(A|H3)/ P(A) = 0,5*0,6 / 0,765 = 0,392
Třetí prvek má maximální pravděpodobnost.
Začněme příkladem. V urně před tebou, se stejnou pravděpodobností mohou být (1) dvě bílé koule, (2) jedna bílá a jedna černá, (3) dvě černé. Přetáhnete míč a ukáže se, že je bílý. Jak byste to ohodnotili nyní? pravděpodobnost tyto tři možnosti (hypotézy)? Je zřejmé, že pravděpodobnost hypotézy (3) se dvěma černými kuličkami = 0. Jak ale vypočítat pravděpodobnosti dvou zbývajících hypotéz!? To lze provést Bayesovým vzorcem, který má v našem případě tvar (číslo vzorce odpovídá číslu testované hypotézy):
Stáhněte si poznámku v nebo
X– náhodná proměnná (hypotéza) nabývající následujících hodnot: x 1- dvě bílé, x 2– jeden bílý, jeden černý; x 3– dvě černé; na– náhodná proměnná (událost) nabývající hodnot: v 1– vytáhne se bílá koule a ve 2– je vytažena černá koule; P(x 1)– pravděpodobnost první hypotézy před vytažením míče ( a priori pravděpodobnost nebo pravděpodobnost na zkušenosti) = 1/3; P(x 2)– pravděpodobnost druhé hypotézy před vytažením míče = 1/3; P(x 3)– pravděpodobnost třetí hypotézy před vytažením míče = 1/3; P(y 1|x 1)– podmíněná pravděpodobnost vytažení bílé koule, pokud platí první hypotéza (koule jsou bílé) = 1; P(y 1|x 2) – pravděpodobnost vytažení bílé koule, pokud platí druhá hypotéza (jedna koule je bílá, druhá černá) = ½; P(y 1|x 3) – pravděpodobnost vytažení bílé koule, pokud je pravdivá třetí hypotéza (obě černé) = 0; P(y 1)– pravděpodobnost vytažení bílé koule = ½; R(y 2)– pravděpodobnost vytažení černé koule = ½; a nakonec, co hledáme - P(x 1|y 1) – pravděpodobnost, že první hypotéza je pravdivá (obě koule jsou bílé), za předpokladu, že jsme vytáhli bílou kouli ( a posteriori pravděpodobnost nebo pravděpodobnost po zažít); P(x 2|y 1) – pravděpodobnost, že druhá hypotéza je pravdivá (jedna kulička je bílá, druhá černá), za předpokladu, že jsme vytáhli bílou kuličku.
Pravděpodobnost, že první hypotéza (dvě bílé) je pravdivá, pokud jsme nakreslili bílou kouli:

Pravděpodobnost, že je druhá hypotéza pravdivá (jedna je bílá, druhá černá), za předpokladu, že jsme vytáhli bílou kouli:

Pravděpodobnost, že třetí hypotéza je pravdivá (dvě černé), za předpokladu, že jsme vytáhli bílou kouli:

Co dělá Bayesův vzorec? Umožňuje na základě apriorních pravděpodobností hypotéz - P(x 1), P(x 2), P(x 3)– a pravděpodobnosti událostí, které nastanou – P(y 1), R(y 2)– vypočítat zadní pravděpodobnosti hypotéz, například pravděpodobnost první hypotézy, za předpokladu, že je vytažena bílá koule – P(x 1|y 1).
Vraťme se ještě jednou ke vzorci (1). Počáteční pravděpodobnost první hypotézy byla P(x 1) = 1/3. S pravděpodobností P(y 1) = 1/2 mohli bychom nakreslit bílou kouli as pravděpodobností P(y2) = 1/2- černá. Vytáhli jsme bílou. Pravděpodobnost kresby bílou za předpokladu, že první hypotéza je pravdivá P(y 1|x 1) = 1. Bayesův vzorec říká, že od vylosování bílé se pravděpodobnost první hypotézy zvýšila na 2/3, pravděpodobnost druhé hypotézy je stále 1/3 a pravděpodobnost třetí hypotézy se stala nulovou.
Je snadné zkontrolovat, že kdybychom vytáhli černou kouli, zadní pravděpodobnosti by se symetricky změnily: P(x 1|y2) = 0, P(x2|y2) = 1/3, P(x 3|y 2) = 2/3.
Zde je to, co Pierre Simon Laplace napsal o Bayesově vzorci v práci publikované v roce 1814:
To je základní princip té větve kontingenční analýzy, která se zabývá přechody od událostí k příčinám.
Proč je Bayesův vzorec tak těžké pochopit!? Podle mého názoru proto, že náš obvyklý přístup je uvažování od příčin k následkům. Pokud je například v urně 36 kuliček, z nichž 6 je černých a zbytek je bílý. Jaká je pravděpodobnost vytažení bílé koule? Bayesův vzorec umožňuje přejít od událostí k důvodům (hypotézám). Pokud bychom měli tři hypotézy a došlo k nějaké události, jak tato událost (a ne alternativa) ovlivnila počáteční pravděpodobnosti hypotéz? Jak se tyto pravděpodobnosti změnily?
Věřím, že Bayesův vzorec není jen o pravděpodobností. Mění paradigma vnímání. Jaký je myšlenkový proces při použití deterministického paradigmatu? Pokud k události došlo, co bylo její příčinou? Kdyby došlo k nehodě, mimořádné události, vojenskému konfliktu. Kdo nebo co byla jejich chyba? Co si myslí Bayesovský pozorovatel? Jaká je struktura reality, která vedla k daný případ k takovému a takovému projevu... Bayesián chápe, že v jinak V tomto případě mohl být výsledek jiný...
Umístíme symboly ve vzorcích (1) a (2) trochu jinak:

Pojďme si znovu promluvit o tom, co vidíme. Se stejnou počáteční (a priori) pravděpodobností by jedna ze tří hypotéz mohla být pravdivá. Se stejnou pravděpodobností bychom mohli nakreslit bílou nebo černou kouli. Vytáhli jsme bílou. Ve světle těchto nových doplňujících informací by naše hodnocení hypotéz mělo být přehodnoceno. Bayesův vzorec nám to umožňuje numericky. Předběžná pravděpodobnost první hypotézy (vzorec 7) byla P(x 1), byla nakreslena bílá koule, zadní pravděpodobnost první hypotézy se stala P(x 1|v 1). Tyto pravděpodobnosti se liší faktorem.
Událost v 1 nazývané důkazy, které více či méně potvrzují nebo vyvracejí hypotézu x 1. Tento koeficient se někdy nazývá síla důkazu. Čím silnější je důkaz (čím více se koeficient liší od jednoty), tím větší je fakt pozorování v 1 mění předchozí pravděpodobnost, tím více se zadní pravděpodobnost liší od předchozí. Pokud jsou důkazy slabé (koeficient ~1), je zadní pravděpodobnost téměř stejná jako předchozí.
Osvědčení v 1 PROTI = 2 časy změnily předchozí pravděpodobnost hypotézy x 1(vzorec 4). Zároveň důkazy v 1 nezměnil pravděpodobnost hypotézy x 2, od své moci = 1 (vzorec 5).
Obecně má Bayesův vzorec následující formu:

X– náhodná proměnná (soubor vzájemně se vylučujících hypotéz) nabývající následujících hodnot: x 1, x 2, … , Xn. na– náhodná proměnná (soubor vzájemně se vylučujících událostí) nabývající následujících hodnot: v 1, ve 2, … , nan. Bayesův vzorec umožňuje najít zadní pravděpodobnost hypotézy Xi při výskytu události y j. Čitatel je součin předchozí pravděpodobnosti hypotézy Xi – P(xi) na pravděpodobnosti výskytu události y j, pokud je hypotéza pravdivá Xi – P(y j|xi). Jmenovatel je součet součinů stejného jako v čitateli, ale pro všechny hypotézy. Pokud vypočítáme jmenovatele, dostaneme celkovou pravděpodobnost, že událost nastane naj(pokud je některá z hypotéz pravdivá) – P(y j) (jako ve vzorcích 1–3).
Ještě jednou o svědectví. Událost y j poskytuje další informace, které vám umožňují revidovat předchozí pravděpodobnost hypotézy Xi. Síla důkazů -  – obsahuje v čitateli pravděpodobnost, že událost nastane y j, pokud je hypotéza pravdivá Xi. Jmenovatel je celková pravděpodobnost, že událost nastane. naj(nebo pravděpodobnost, že k události dojde naj zprůměrováno přes všechny hypotézy). naj výše pro hypotézu xi, než je průměr za všechny hypotézy, pak důkazy hrají do karet hypotéze xi, čímž se zvyšuje jeho zadní pravděpodobnost P(y j|xi).
Pokud je pravděpodobnost výskytu události naj níže pro hypotézu xi než je průměr všech hypotéz, pak důkaz snižuje zadní pravděpodobnost P(y j|xi) Pro hypotézy xi.
Pokud pravděpodobnost výskytu události naj pro hypotézu xi je stejný jako průměr pro všechny hypotézy, pak důkaz nemění zadní pravděpodobnost P(y j|xi) Pro hypotézy xi.
– obsahuje v čitateli pravděpodobnost, že událost nastane y j, pokud je hypotéza pravdivá Xi. Jmenovatel je celková pravděpodobnost, že událost nastane. naj(nebo pravděpodobnost, že k události dojde naj zprůměrováno přes všechny hypotézy). naj výše pro hypotézu xi, než je průměr za všechny hypotézy, pak důkazy hrají do karet hypotéze xi, čímž se zvyšuje jeho zadní pravděpodobnost P(y j|xi).
Pokud je pravděpodobnost výskytu události naj níže pro hypotézu xi než je průměr všech hypotéz, pak důkaz snižuje zadní pravděpodobnost P(y j|xi) Pro hypotézy xi.
Pokud pravděpodobnost výskytu události naj pro hypotézu xi je stejný jako průměr pro všechny hypotézy, pak důkaz nemění zadní pravděpodobnost P(y j|xi) Pro hypotézy xi.
Zde je několik příkladů, které, jak doufám, posílí vaše pochopení Bayesova vzorce.
Úkol 2. Dva střelci nezávisle střílejí na stejný cíl, každý vystřelí jednu ránu. Pravděpodobnost zasažení cíle pro prvního střelce je 0,8, pro druhého - 0,4. Po střelbě byla objevena jedna díra v terči. Najděte pravděpodobnost, že tato jamka patří prvnímu střelci. .
Úloha 3. Monitorovaný objekt může být v jednom ze dvou stavů: H 1 = (funkční) a H 2 = (nefunkční). Přednostní pravděpodobnosti těchto stavů jsou P(H 1) = 0,7, P(H 2) = 0,3. Existují dva zdroje informací, které poskytují protichůdné informace o stavu objektu; první zdroj hlásí, že objekt nefunguje, druhý - že funguje. Je známo, že první zdroj poskytuje správné informace s pravděpodobností 0,9 as pravděpodobností 0,1 - nesprávné informace. Druhý zdroj je méně spolehlivý: poskytuje správné informace s pravděpodobností 0,7 a nesprávné s pravděpodobností 0,3. Najděte pozdější pravděpodobnosti hypotéz. .
Úlohy 1–3 jsou převzaty z učebnice E.S. Ventzela, L.A. Ovcharova. Teorie pravděpodobnosti a její inženýrské aplikace, oddíl 2.6 Věta o hypotéze (Bayesův vzorec).
Problém 4 převzat z knihy, oddíl 4.3 Bayesova věta.
Bayesův vzorec
Bayesova věta- jedna z hlavních vět elementární teorie pravděpodobnosti, která určuje pravděpodobnost události nastávající za podmínek, kdy jsou na základě pozorování známy jen některé dílčí informace o událostech. Pomocí Bayesova vzorce je možné přepočítat pravděpodobnost přesněji s přihlédnutím jak k dříve známým informacím, tak údajům z nových pozorování.
"Fyzikální význam" a terminologie
Bayesův vzorec umožňuje „přeuspořádat příčinu a následek“: na základě známé skutečnosti události vypočítat pravděpodobnost, že byla způsobena danou příčinou.
Události odrážející působení „příčin“ se v tomto případě obvykle nazývají hypotézy, protože jsou údajný události, které k tomu vedly. Bezpodmínečná pravděpodobnost, že hypotéza je pravdivá, se nazývá a priori(jak pravděpodobný je důvod vůbec), a podmíněné – s přihlédnutím ke skutečnosti události – a posteriori(jak pravděpodobný je důvod ukázalo se, že bere v úvahu data události).
Následek
Důležitým důsledkem Bayesova vzorce je vzorec pro celkovou pravděpodobnost události v závislosti na několik nekonzistentní hypotézy ( a jen od nich!).
 - pravděpodobnost výskytu události B v závislosti na řadě hypotéz A i, pokud je znám stupeň spolehlivosti těchto hypotéz (například měřeno experimentálně);
- pravděpodobnost výskytu události B v závislosti na řadě hypotéz A i, pokud je znám stupeň spolehlivosti těchto hypotéz (například měřeno experimentálně); Odvození vzorce
Pokud událost závisí pouze na příčinách A i, pak pokud se to stalo, znamená to, že musel nastat jeden z důvodů, tzn.
Podle Bayesova vzorce

Převodem P(B) napravo získáme požadovaný výraz.
Metoda filtrování spamu
Metoda založená na Bayesově teorému našla úspěšné uplatnění při filtrování spamu.
Popis
Při trénování filtru se pro každé slovo vyskytující se v písmenech vypočítá a uloží jeho „váha“ – pravděpodobnost, že písmeno s tímto slovem je spam (v nejjednodušším případě – podle klasické definice pravděpodobnosti: „objevení se ve spamu / vzhledy celkem“).
Při kontrole nově příchozího dopisu se pravděpodobnost, že se jedná o spam, vypočítává pomocí výše uvedeného vzorce pro různé hypotézy. V tomto případě jsou „hypotézy“ slova a pro každé slovo je „spolehlivost hypotézy“ % tohoto slova v písmenu a „závislost události na hypotéze“ P(B | A i) - dříve vypočítaná „váha“ slova. To znamená, že „váha“ dopisu v tomto případě není nic jiného než průměrná „váha“ všech jeho slov.
Dopis je klasifikován jako „spam“ nebo „non-spam“ podle toho, zda jeho „váha“ přesahuje určitou úroveň určenou uživatelem (obvykle 60–80 %). Po rozhodnutí o písmenu se v databázi aktualizují „váhy“ slov v něm obsažených.
Charakteristický
Tato metoda je jednoduchá (algoritmy jsou elementární), pohodlná (umožňuje obejít se bez „černých listin“ a podobných umělých technik), účinná (po natrénování na dostatečně velkém vzorku odstraní až 95–97 % spamu a v případě jakýchkoliv chyb jej lze přeškolit). Obecně vše nasvědčuje jeho širokému použití, což se v praxi děje – na jeho základě jsou postaveny téměř všechny moderní spamové filtry.
Metoda má však také zásadní nevýhodu: je na základě předpokladu, co některá slova jsou běžnější ve spamu, zatímco jiná jsou běžnější v běžných e-mailech a je neúčinný, pokud je tento předpoklad nesprávný. Jak však ukazuje praxe, ani člověk nemůže takový spam odhalit „okem“ - pouze přečtením dopisu a pochopením jeho významu.
Další ne zásadní nevýhodou související s implementací je, že metoda pracuje pouze s textem. S vědomím tohoto omezení začali spameři do obrázku vkládat reklamní informace, ale text v dopise buď chyběl, nebo neměl smysl. Abyste tomu zabránili, musíte použít buď nástroje pro rozpoznávání textu ("drahý" postup, který se používá pouze v nezbytně nutných případech), nebo staré metody filtrování - "černé listiny" a regulární výrazy (protože taková písmena mají často stereotypní tvar).
Viz také
Poznámky
Odkazy
Literatura
- Ptačí kiwi. Věta reverenda Bayese. // Časopis Computerra, 24. srpna 2001.
- Paul Graham. Plán pro spam (anglicky). // Osobní stránky Paula Grahama.
Nadace Wikimedia.
2010.
Podívejte se, co je „Bayesův vzorec“ v jiných slovnících: Vzorec, který má tvar: kde a1, A2,..., An jsou neslučitelné děje, Obecné schéma aplikace f.v. g.: jestliže událost B může nastat v různých. podmínky, o kterých bylo vytvořeno n hypotéz A1, A2, ..., An s pravděpodobnostmi P(A1), ... známými před experimentem.
Geologická encyklopedie
Umožňuje vypočítat pravděpodobnost události zájmu prostřednictvím podmíněných pravděpodobností této události za předpokladu určitých hypotéz a také pravděpodobností těchto hypotéz. Formulace Nechť je dán pravděpodobnostní prostor a celá skupina ve dvojicích... ... Wikipedie
Umožňuje vypočítat pravděpodobnost události zájmu prostřednictvím podmíněných pravděpodobností této události za předpokladu určitých hypotéz a také pravděpodobností těchto hypotéz. Formulace Nechť je dán prostor pravděpodobnosti a úplná skupina událostí jako... ... Wikipedie
- (neboli Bayesův vzorec) je jedním z hlavních teorémů teorie pravděpodobnosti, který umožňuje určit pravděpodobnost, že k nějaké události (hypotéze) došlo za přítomnosti pouze nepřímých důkazů (dat), které mohou být nepřesné... Wikipedie
Bayesův teorém je jedním z hlavních teorémů elementární teorie pravděpodobnosti, který určuje pravděpodobnost, že událost nastane za podmínek, kdy jsou na základě pozorování známy pouze některé dílčí informace o událostech. Pomocí Bayesova vzorce můžete... ... Wikipedie
Bayes, Thomas Thomas Bayes Reverend Thomas Bayes Datum narození: 1702 (1702) Místo narození ... Wikipedia
Bayesovská inference je jednou z metod statistické inference, ve které se Bayesův vzorec používá k upřesnění pravděpodobnostních odhadů pravdivosti hypotéz, když jsou obdrženy důkazy. Použití bayesovské aktualizace je obzvláště důležité v... ... Wikipedii
Pro vylepšení tohoto článku je žádoucí?: Najděte a uspořádejte ve formě poznámek pod čarou odkazy na věrohodné zdroje potvrzující to, co bylo napsáno. Po přidání poznámek pod čarou uveďte přesnější údaje o zdrojích. Pere... Wikipedie
Zradí se vězni navzájem podle svých sobeckých zájmů, nebo budou mlčet, čímž se sníží celkový trest? Prisoner's dilemma (anglicky: Prisoner's dilemma, méně často se používá název „dilemma ... Wikipedia
knihy
- Teorie pravděpodobnosti a matematická statistika v úlohách: Více než 360 úloh a cvičení, D. Borzykh Navrhovaná příručka obsahuje problémy různé úrovně složitosti. Hlavní důraz je však kladen na úlohy střední složitosti. To se děje záměrně s cílem povzbudit studenty, aby...
Sibiřská státní univerzita telekomunikací a informatiky
Katedra vyšší matematiky
v oboru: „Teorie pravděpodobnosti a matematická statistika“
"Vzorec celkové pravděpodobnosti a vzorec Bayes (Bayes) a jejich aplikace"
Dokončeno:
Vedoucí: Profesor B.P. Zelentsov
Novosibirsk, 2010
Úvod 3
1. Vzorec celkové pravděpodobnosti 4-5
2. Bayesův vzorec (Bayes) 5-6
3. Problémy s řešením 7-11
4. Hlavní oblasti použití Bayesova vzorce (Bayes) 11
Závěr 12
Literatura 13
Zavedení
Teorie pravděpodobnosti je jedním z klasických odvětví matematiky. Má dlouhou historii. Základy tohoto vědního oboru položili velcí matematici. Budu jmenovat např. Fermat, Bernoulli, Pascal.
Později byl vývoj teorie pravděpodobnosti určen v pracích mnoha vědců.
Vědci z naší země významně přispěli k teorii pravděpodobnosti:
P.L.Čebyšev, A.M.Ljapunov, A.A.Markov, A.N.Kolmogorov. Pravděpodobnostní a statistické metody nyní pronikly hluboko do aplikací. Používají se ve fyzice, technice, ekonomii, biologii a medicíně. Jejich role vzrostla zejména v souvislosti s rozvojem výpočetní techniky.
Například ke studiu fyzikálních jevů se provádějí pozorování nebo experimenty. Jejich výsledky jsou obvykle zaznamenávány ve formě hodnot některých pozorovatelných veličin. Při opakování experimentů objevíme rozptyl jejich výsledků. Například opakováním měření stejné veličiny stejným zařízením při zachování určitých podmínek (teplota, vlhkost atd.) získáme výsledky, které se od sebe alespoň trochu liší. Ani opakovaná měření neumožňují přesně předpovědět výsledek dalšího měření. V tomto smyslu říkají, že výsledkem měření je náhodná veličina. Ještě zřetelnějším příkladem náhodné veličiny je číslo výherního tiketu v loterii. Lze uvést mnoho dalších příkladů náhodných proměnných. Přesto se ve světě náhody určité vzorce odhalují. Matematický aparát pro studium takových vzorů poskytuje teorie pravděpodobnosti.
Teorie pravděpodobnosti se tedy zabývá matematickou analýzou náhodných událostí a souvisejících náhodných proměnných.
1. Vzorec celkové pravděpodobnosti.
Nechť je skupina akcí H 1 ,H 2 ,..., Hn, který má následující vlastnosti:
1) všechny události jsou párově nekompatibilní: H i
Hj =Æ; i , j =1,2,...,n ; i ¹ j ;2) jejich spojení tvoří prostor elementárních výsledků W:
 |
| Obr.8 |
V tomto případě to řekneme H 1 , H 2 ,...,Hn formulář celá skupina akcí. Takovým událostem se někdy říká hypotézy .
Nechat A- nějaká akce: AÌW (Venn diagram je znázorněn na obrázku 8). Pak to drží vzorec celkové pravděpodobnosti:
P (A) = P (A /H 1)P (H 1) + P (A /H 2)P (H 2) + ...+P (A /Hn)P (Hn) =

Důkaz. Samozřejmě: A=
a všechny události ( i = 1,2,...,n) jsou párově nekonzistentní. Odtud pomocí sčítacího teorému pravděpodobností dostávámeP (A) = P (
) + P () +...+ P (Když to vezmeme v úvahu násobící větou P (
) = P (A/H i) P (H i) ( i = 1,2,...,n), pak z posledního vzorce lze snadno získat výše uvedený vzorec celkové pravděpodobnosti.Příklad. Prodejna prodává elektrické lampy vyrobené třemi továrnami, přičemž první továrna má podíl 30 %, druhá 50 % a třetí 20 %. Vady jejich výrobků jsou 5 %, 3 % a 2 %. Jaká je pravděpodobnost, že se náhodně vybraná lampa v obchodě ukáže jako vadná?
Nechte událost H 1 je, že vybraná lampa je vyrobena v první továrně, H 2 na druhém, H 3 - u třetího závodu. Samozřejmě:
P (H 1) = 3/10, P (H 2) = 5/10, P (H 3) = 2/10.
Nechte událost A je, že se ukázalo, že vybraná lampa je vadná; A/H i znamená případ, že je vadná žárovka vybrána ze žárovek vyrobených v i-ta rostlina. Z výpisu problému vyplývá:
P (A / H 1) = 5/10; P (A / H 2) = 3/10; P (A / H 3) = 2/10
Pomocí vzorce celkové pravděpodobnosti dostaneme

2. Bayesův vzorec (Bayes)
Nechat H 1 ,H 2 ,...,Hn- kompletní skupina akcí a AМ W je nějaká událost. Pak podle vzorce pro podmíněnou pravděpodobnost
Zde P (Hk /A) – podmíněná pravděpodobnost události (hypotéza) Hk nebo pravděpodobnost, že Hk se realizuje za předpokladu, že event A stalo.
Podle věty o násobení pravděpodobnosti může být čitatel vzorce (1) reprezentován jako
P = P = P (A /Hk)P (Hk)
K vyjádření jmenovatele vzorce (1) můžete použít vzorec celkové pravděpodobnosti
P (A)
Nyní z (1) můžeme získat vzorec nazvaný Bayesův vzorec :

Bayesův vzorec počítá pravděpodobnost realizace hypotézy Hk za předpokladu, že událost A stalo. Bayesův vzorec se také nazývá vzorec pro pravděpodobnost hypotéz. Pravděpodobnost P (Hk) se nazývá předchozí pravděpodobnost hypotézy Hk a pravděpodobnost P (Hk /A) – zadní pravděpodobnost.
Teorém. Pravděpodobnost hypotézy po testu se rovná součinu pravděpodobnosti hypotézy před testem a odpovídající podmíněné pravděpodobnosti události, která nastala během testu, dělené celkovou pravděpodobností této události.
Příklad. Zvažme výše uvedený problém o elektrických lampách, stačí změnit otázku problému. Předpokládejme, že si zákazník v tomto obchodě zakoupil elektrickou lampu a ukázalo se, že je vadná. Najděte pravděpodobnost, že tato lampa byla vyrobena ve druhém závodě. Velikost P (H 2) = 0,5 v tomto případě je apriorní pravděpodobnost události, že zakoupená lampa byla vyrobena ve druhém závodě. Po obdržení informace, že zakoupená lampa je vadná, můžeme opravit náš odhad možnosti výroby této lampy ve druhém závodě výpočtem zadní pravděpodobnosti této události.